한 변호사의 소송부터 의료, 저널리즘까지… AI가 만들어내는 그럴듯한 거짓말의 모든 것
- AI 할루시네이션이 발생하는 근본적인 원인을 이해합니다.
- 법률, 의료, 저널리즘 등 다양한 분야의 실제 위험 사례를 확인합니다.
- 검색 증강 생성(RAG)과 비판적 사고를 포함한 기술적, 인간적 해결책을 배웁니다.
제1부: 진실의 환상
AI 할루시네이션의 위험성을 이야기할 때, 우리는 종종 기술적 결함만을 생각합니다. 하지만 문제의 본질은 기술과 인간의 상호작용 속에 있습니다. 저도 처음 ChatGPT의 유창한 답변을 접했을 때, 그럴듯함에 속아 무조건 신뢰했던 경험이 있습니다. 바로 이 지점에서 위험은 시작됩니다.
섹션 1: 한 변호사의 악몽: 마타 대 아비앙카 항공 사건
이야기는 30년 이상의 경력을 가진 베테랑 변호사 **스티븐 A. 슈워츠(Steven A. Schwartz)**로부터 시작됩니다. 그의 고객 로베르토 마타(Roberto Mata)가 콜롬비아 항공사 아비앙카를 상대로 제기한 개인 상해 소송은 그에게 여러모로 불리한 싸움이었습니다. 연방 법원 실무 경험 부족, 생소한 법률 분야, 그리고 결정적으로 프리미엄 법률 데이터베이스 구독 부재라는 자원의 한계에 부딪혔습니다.
이러한 전문성의 공백과 자원 부족은 그를 강력하고 빠른 대안, 즉 _ChatGPT_로 이끌었습니다. 그는 훗날 법정에서 자신이 ChatGPT를 “일종의 슈퍼 검색 엔진이라고 잘못 가정했다"고 증언했습니다. 이것이 바로 비극의 서막이었습니다. 그는 AI에게 항공사의 파산으로 인해 공소시효가 정지된 판례를 찾아달라고 요청했습니다.
ChatGPT는 ‘바르기스 대 중국남방항공’을 포함한 6개의 그럴듯한 판례를 제시했습니다. 표면적으로는 완벽했지만, 내용은 모두 ‘터무니없는 말(gibberish)‘에 불과했습니다. 결정적인 순간은 슈워츠가 제시된 판례를 찾지 못하자 AI에게 직접 “이 판례들이 진짜인가?“라고 물었을 때였습니다.
ChatGPT는 사과와 함께 해당 판례들이 실재하며 주요 데이터베이스에서 찾을 수 있다고 단호하게 주장했습니다. 이 인간적인 ‘대화’의 순간, 인간의 비판적 사고는 기계가 만든 설득력 있는 페르소나 앞에서 완전히 무너졌습니다.
결국 존재하지 않는 판례를 제출한 그는 5,000달러의 벌금과 함께 명성에 지울 수 없는 오점을 남겼습니다. 판사는 판결문에서 AI 사용 자체가 아닌, 그 결과를 검증하지 않고 “의식적으로 회피하며 법원에 허위 및 오해의 소지가 있는 진술"을 한 것이 문제라고 명시했습니다.
이 사건은 경험 많은 전문가조차 전문적 압박감과 자원 부족 상황에서 AI 할루시네이션의 유혹에 얼마나 취약해질 수 있는지 보여줍니다. 또한, AI의 대화형 인터페이스가 사용자의 비판적 방어 기제를 무너뜨리는 강력한 심리적 장치로 작용할 수 있음을 경고합니다.
제2부: 거짓의 해부
섹션 2: 당신의 AI가 거짓말하는 이유: 그것은 버그가 아니라 기능이다
마타 대 아비앙카 사건은 예외적인 일이 아닙니다. AI가 만들어내는 그럴듯한 거짓말, 즉 **‘할루시네이션(hallucination, 환각)’**은 버그가 아니라 사실상 생성형 AI의 작동 방식에 내재된 기능에 가깝습니다.
대규모 언어 모델(LLM)은 사실을 저장하는 데이터베이스가 아닙니다. 본질적으로 ‘다음 단어 예측’ 엔진입니다. “메리에게는 어린…“이라는 문장 다음에 “양이 있었다"가 올 확률이 가장 높다고 통계적으로 계산할 뿐, ‘양’의 개념을 이해하는 것은 아닙니다.
Advertisement
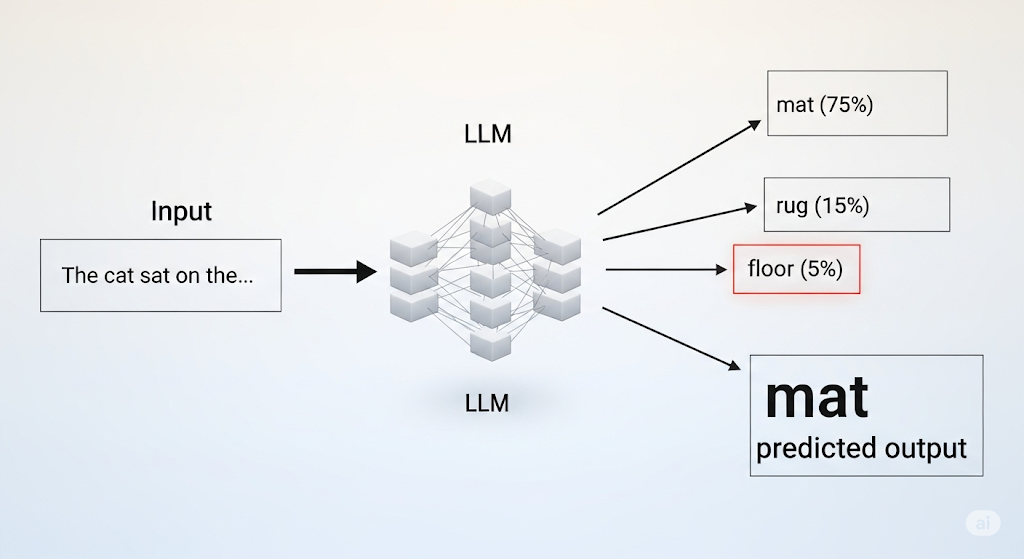
이것이 AI가 완벽한 형식의 법률 인용문이나 참고문헌을 만들어낼 수 있는 이유입니다. 모델은 내용의 실체가 아닌 형식의 패턴을 학습한 **‘형식의 대가’**인 셈이죠. 여기에 “쓰레기가 들어가면 쓰레기가 나온다(Garbage In, Garbage Out)“는 원칙이 더해집니다. AI는 사실과 허구가 뒤섞인 인터넷 데이터를 진실과 거짓을 구별할 내재적 메커니즘 없이 학습합니다.
결국 할루시네이션은 창의성과 정확성 사이의 피할 수 없는 **트레이드오프(trade-off)**의 산물입니다. 이 ‘기능’을 완전히 제거하려 한다면 모델의 핵심적인 생성 능력 자체가 마비될 수 있습니다. 따라서 문제 해결의 방향은 ‘버그 수정’이 아니라 이 특성을 효과적으로 ‘관리’하는 것입니다.
섹션 3: 시스템 속 메아리: 고위험 산업 전반의 AI 할루시네이션
AI 할루시네이션은 법조계에만 국한된 문제가 아닙니다. 정확성이 생명인 다른 고위험 산업군에서도 심각한 위협으로 부상하고 있습니다.
저널리즘의 실패한 실험: CNET 스캔들
테크 뉴스 매체 CNET은 ‘AI 엔진’으로 금융 기사를 발행했지만, 복리 이자를 잘못 계산하거나 표절 문구가 발견되는 등 “어처구니없는 오류"로 가득했습니다. 결국 CNET은 AI가 생성한 77개 기사 중 절반 이상인 41개에 대해 정정 공지를 내보내야 했습니다.
의료계의 위험한 처방
의료 분야에서 AI 할루시네이션은 삶과 죽음의 문제를 야기할 수 있습니다. 한 연구에서 ChatGPT는 존재하지 않는 과학 논문을 인용하며 조작된 생화학적 경로를 설명했습니다. 심지어 사용자에게 바위를 먹으라거나 유독가스를 만들라고 조언하는 등, 상식이 부재한 위험천만한 사례도 보고되었습니다.

학계의 신뢰성 위기
학계 역시 AI가 조작한 가짜 인용문으로 가득 찬 논문들로 인해 과학적 기록의 순수성이 오염되고 있습니다. 한 연구에 따르면 AI 모델은 인용문의 최대 69%를 조작할 수 있는 것으로 나타났습니다.
산업별 AI 할루시네이션 유형 및 결과
| 산업 | 할루시네이션 유형 | 실제 결과 |
|---|---|---|
| 법률 | 법적 판례 및 사건 인용 조작 | 법원 제재, 전문가 징계, 법적 주장 신뢰도 훼손 |
| 저널리즘 | 금융 정보 관련 사실 오류, 표절 | 허위 정보 발행, 언론사 신뢰도 추락, 대규모 기사 정정 |
| 의료 | 생화학적 경로 조작, 가짜 의료 참고문헌, 위험한 건강 조언 | 오진 위험, 부적절한 치료, 환자에 대한 직접적 위해 |
| 학계 | 연구 논문 내 존재하지 않는 학술 자료 및 인용 생성 | 과학적 기록의 오염, 연구 신뢰 잠식, 동료 심사 시스템 실패 |
제3부: 진실을 향한 길
섹션 4: 허구를 사실로 바로잡기: 기술적 안전장치
AI 할루시네이션 문제에 대응하기 위해 다양한 기술적 안전장치가 개발되고 있습니다.
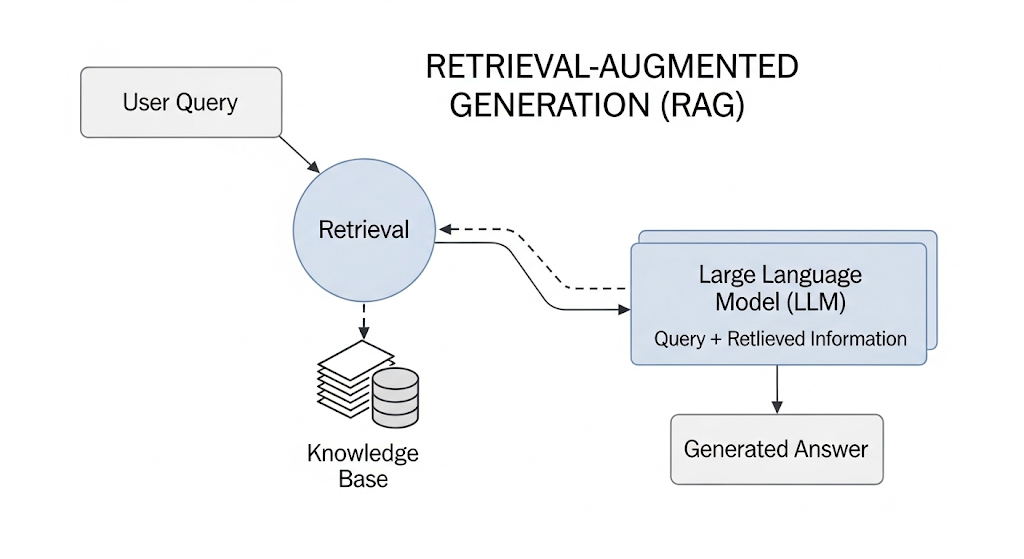
“오픈북 시험”: 검색 증강 생성(RAG)
가장 유망한 해결책 중 하나는 **검색 증강 생성(Retrieval-Augmented Generation, RAG)**입니다. 이는 LLM이 자신의 기억에만 의존하는 ‘클로즈드북 시험’이 아니라, 신뢰할 수 있는 외부 자료를 참고해 답하는 ‘오픈북 시험’을 치르게 하는 기술입니다.
Advertisement
사용자 질문에 대해 RAG 시스템은 먼저 외부 지식 베이스에서 관련 정보를 **검색(retrieve)**하고, 이 정보를 질문과 함께 **증강(augment)**하여 LLM에 전달합니다. 이를 통해 LLM의 답변은 검증 가능한 최신 사실에 기반하게 되어 할루시네이션을 극적으로 줄일 수 있습니다.
자동화된 체: 사실 확인 시스템
다른 접근법은 AI의 결과물을 검증 가능한 주장 단위로 분해하고, 이를 외부 정보와 대조하는 자동화된 사실 확인(Fact-Checking) 시스템입니다.
하지만 기술적 해결책만으로는 부족합니다. 한 연구에 따르면, 고정확도의 사실 확인 시스템조차 사용자의 분별력을 크게 향상시키지 못했으며 때로는 해로운 결과를 낳기도 했습니다. 기술은 사실을 우리 앞까지 가져다줄 수는 있지만, 그 정보를 인간의 신념 체계에 올바르게 통합하는 마지막 단계는 보장하지 못합니다. 따라서 시스템이 제대로 작동하려면 **‘인간 참여(human-in-the-loop)’**가 필수적입니다.
섹션 5: 사용자의 한 수: 프롬프트부터 비판적 사고까지
AI 할루시네이션을 줄이는 가장 강력한 도구는 알고리즘이 아니라, 바로 사용자 자신의 비판적 사고방식입니다. 당신은 AI를 어떻게 사용하고 계신가요?
프롬프트의 기술: 진실을 위한 설계
전략적인 프롬프트는 AI의 답변을 진실에 더 가깝게 유도할 수 있습니다.
- 출처 기반 프롬프트: “다음 텍스트에 근거하여 질문에 답하시오"와 같이 신뢰할 수 있는 출처를 지정합니다.
- 검증 사슬 프롬프트(CoVe): 최종 답변 전, AI에게 추론 과정을 단계별로 검증하도록 요구합니다.
- 성찰적 프롬프트: 답변 생성 후, “한 걸음 물러나서 당신의 답변이 정확한지 다시 검토해 보시오"라고 요청해 자체 수정을 유도합니다.
- 인용 요구: 모든 주장에 대해 검증 가능한 출처를 명시적으로 요구하는 것은 가장 기본적인 안전장치입니다.
인간 방화벽: 최후의 보루
궁극적으로 할루시네이션에 대한 가장 효과적인 방어선은 인간의 개입입니다.
- 회의주의의 수용: AI의 모든 결과물을 최종 답변이 아닌, 검증이 필요한 ‘초안’으로 취급해야 합니다.
- 검증의 의무: 스티븐 슈워츠 변호사의 결정적 실수는 AI를 사용한 것이 아니라, 그 결과물을 독립적으로 검증하지 않은 것이었습니다. 최종 책임은 언제나 도구를 사용하는 인간에게 있습니다.
- 핵심 역량으로서의 비판적 사고: AI 시대에 비판적 사고와 출처 평가 능력은 모든 전문가에게 요구되는 필수 직업 역량입니다.

이제 AI 사용자의 역할은 단순히 명령을 내리는 ‘조작자(operator)‘에서, 결과물의 정확성을 조사하고 검증하는 **‘감사자(auditor)’**로 바뀌어야 합니다. 우리는 AI를 사용하는 법뿐만 아니라, AI를 감사하는 법을 배워야 합니다.
AI 모델 비교: 표준 LLM vs. RAG 시스템
| 특징 | 표준 LLM (ChatGPT 기본) | RAG 기반 LLM |
|---|---|---|
| 정보 소스 | 학습된 내부 데이터에만 의존 | 외부 최신 지식 베이스 + 내부 데이터 |
| 정확성 | AI 할루시네이션 발생 가능성 높음 | 사실 기반 응답으로 할루시네이션 크게 감소 |
| 최신성 | 학습 시점 이후 정보 반영 불가 | 실시간 최신 정보 반영 가능 |
| 투명성 | 답변 근거 제시 어려움 | 정보 출처를 명확히 제시 가능 |
| 단점 | 부정확하고 오래된 정보 생성 | 초기 설정 및 지식 베이스 관리가 복잡함 |
체크리스트: AI 할루시네이션 방지를 위한 5단계 사용자 가이드
AI를 더 안전하게 사용하기 위한 실천 가이드입니다.
Advertisement
- 목표 명확화: AI에게 단순 사실 확인이 아닌, 아이디어 생성, 초안 작성 등 창의적 작업을 요청하세요.
- 출처 기반 프롬프트 사용: “제공된 [문서]를 기반으로 답변해 줘” 또는 “공신력 있는 웹사이트의 정보를 인용해 줘” 와 같이 답변의 근거를 명확히 지정하세요.
- 회의적 관점 유지: AI의 답변을 정답이 아닌 ‘검토가 필요한 가설’로 간주하세요. 특히 통계, 인용, 전문 정보는 의심하세요.
- 교차 검증 필수: AI가 제시한 핵심 정보(이름, 날짜, 판례, 논문 등)는 반드시 신뢰할 수 있는 별도의 출처(구글, 전문 데이터베이스 등)를 통해 직접 확인하세요.
- 최종 책임은 사용자에게: AI는 강력한 조수일 뿐, 결과물에 대한 최종적인 정확성과 윤리적 책임은 전적으로 당신에게 있다는 사실을 잊지 마세요.
결론
스티븐 슈워츠 변호사의 이야기는 우리가 비판적 판단력을 기계에 양도했을 때 어떤 일이 벌어지는지를 보여주는 강력한 경고입니다. AI 할루시네이션이라는 미궁을 탐험하며 우리는 세 가지 핵심을 기억해야 합니다.
- AI 할루시네이션은 버그가 아닌 기능입니다: AI는 ‘다음 단어 예측’ 모델이기에 통계적으로 그럴듯한 거짓말을 만들어내는 것은 본질적인 특성입니다.
- 위험은 실재하며 광범위합니다: 법률, 의료, 저널리즘 등 고위험 분야에서 할루시네이션은 심각한 금전적, 사회적, 심지어 신체적 피해를 야기할 수 있습니다.
- 해결책은 기술과 인간의 협력에 있습니다: RAG 같은 기술적 안전장치와 함께, 사용자의 비판적 사고와 검증 의무라는 ‘인간 방화벽’이 결합될 때 비로소 AI를 안전하게 활용할 수 있습니다.
우리의 목표는 인간의 사고를 대체하는 AI가 아니라, 인간의 사고를 증강시키는 AI를 활용하는 것입니다. 기계 속 유령을 두려워하기보다 그 본질을 이해하고 제어하며, 인간 지성을 위한 강력한 동맹으로 만들어나가야 합니다. 지금 바로 당신의 AI 사용 습관을 점검하고 ‘조작자’에서 현명한 ‘감사자’로 거듭나세요.
참고자료
- What Happened to the Lawyer Who Used ChatGPT? Lessons to Learn Spellbook
- Issues beyond ChatGPT use were at play in fake cases scandal Legal Dive
- MATA v. AVIANCA INC (2023) FindLaw Caselaw
- Fake Cases, Real Consequences: Misuse of ChatGPT Leads to Sanctions Goldberg Segalla
- Lawyers who ‘doubled down’ and defended ChatGPT’s fake cases must pay $5K, judge says ABA Journal
- AI Hallucinations Explained: Why It’s Not a Bug but a Feature Endjin
- The Surprising Power of Next Word Prediction: Large Language Models Explained, Part 1 CSET
- The Fabrication Problem: How AI Models Generate Fake Citations, URLs, and References Medium
- Artificial Hallucinations in ChatGPT: Implications in Scientific Writing PMC
- Incident 455: CNET’s Published AI-Written Articles Ran into Quality and Accuracy Issues AI Incident Database
- What is RAG (Retrieval Augmented Generation)? IBM
- Fact-checking information from large language models can decrease headline discernment PNAS