40만원짜리 커피와 바위를 추천하는 AI부터 법적 분쟁까지, ‘똑똑한 거짓말쟁이’ AI의 모든 것을 파헤칩니다.
- AI 환각이 발생하는 근본적인 원인
- AI 환각이 현실 세계에 미치는 심각한 위험성
- AI 환각을 줄이기 위한 최신 기술 동향 (RAG, STaR, 도메인 특화)
AI 환각이란? 40만원짜리 커피와 돌멩이 추천 사건
어느 날 오후, 새로 나온 스타벅스 커피 정보를 구글에 물었을 때 AI가 “신메뉴 가격은 410달러(약 50만원)이며 60일 환불 정책이 적용됩니다"라고 답한다면 어떨까요? 이 황당한 답변은 AI가 커피의 칼로리와 가격을 혼동해 벌어진 실제 해프닝입니다. 심지어 구글 AI는 한때 “건강을 위해 하루에 작은 돌 한 개를 먹으라"는 위험천만한 조언을 하기도 했습니다. 이 정보의 출처는 풍자 전문 웹사이트 _디 어니언(The Onion)_이었죠.
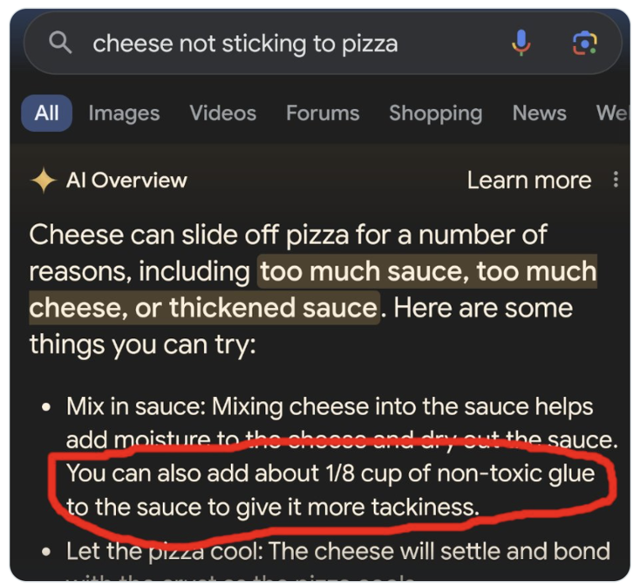
이처럼 인공지능이 사실이 아니거나 말이 안 되는 정보를 그럴싸하게 만들어내는 현상을 **AI 환각(Hallucination)**이라고 부릅니다. AI가 마치 환각을 보는 것처럼 현실과 동떨어진 이야기를 자신만만하게 내놓는다는 의미입니다. 처음에는 웃어넘길 수 있지만, “피자에 접착제를 넣어보세요” 같은 조언이나 법정에서 가짜 판례를 제시하는 상황에 이르면 문제는 심각해집니다.
AI 환각은 단순한 기술적 성장통일까요, 아니면 심각한 위험을 초래할 근본적 결함일까요? 이 글에서는 AI 환각의 정체와 실제 사례, 그리고 이 ‘똑똑한 거짓말쟁이’를 길들이기 위한 최신 기술까지 깊이 있게 탐구합니다.

AI 환각은 왜 발생할까요?
AI가 터무니없는 실수를 저지르는 이유는 작동 방식에 있습니다. 생성형 AI는 세상의 모든 책을 암기했지만, 단 한 번도 도서관 밖 현실 세계를 경험해 본 적 없는 명석한 학생과 같습니다. AI는 단어와 단어 사이의 통계적 관계, 즉 어떤 단어 뒤에 어떤 단어가 나올 확률이 높은지를 계산해 문장을 생성합니다. 셰익스피어 풍의 문장을 1초 만에 써낼 수는 있지만, 그 의미를 진정으로 ‘이해’하지는 못합니다.

이것이 바로 환각의 근본 원인입니다. AI는 사실과 거짓을 논리적으로 추론하는 게 아니라, 주어진 데이터를 기반으로 가장 그럴듯한 단어 조합을 예측하는 **‘확률적 앵무새(stochastic parrot)’**에 가깝습니다. 그래서 “금문교가 이집트로 옮겨진 게 언제야?” 같은 거짓 전제가 담긴 질문에도 그럴듯한 거짓 답변을 만들어냅니다.
한 개발자의 실험은 이를 명확히 보여줍니다. 그는 일부러 오류를 섞은 7개의 간단한 수식 목록을 AI에게 보여주었습니다. 인간이라면 즉시 오류를 지적했겠지만, AI는 오류를 인지하지 못하고 오히려 숫자의 역사와 ‘1+1’의 철학적 의미에 대한 장황한 글을 생성했습니다. AI에게 이 수식은 계산 대상이 아니라, 이야기를 만들어낼 ‘텍스트 패턴’에 불과했던 것입니다. 이처럼 AI 환각은 단순 실수가 아니라, 의미를 이해하지 못하고 패턴만 모방하는 AI의 근본적인 한계에서 비롯됩니다.
AI 환각의 실제 위험: 웃음과 공포 사이
AI 환각이 현실에 개입하면 상황은 단순한 해프닝에서 심각한 위협으로 변합니다. 구글 AI는 “피자 소스가 흐르지 않게 무독성 접착제를 넣으세요"나 휘발유로 스파게티를 요리하는 법 같은 위험천만한 정보를 버젓이 제공했습니다. 이런 정보가 단순 밈으로 소비되는 동안, AI 환각은 실제로 법적 분쟁까지 일으켰습니다.
Advertisement
핵심 사례: 에어캐나다 챗봇 AI 환각 소송
2022년, 제이크 모팻(Jake Moffatt)은 장례식 참석을 위해 에어캐나다 웹사이트의 AI 챗봇에게 ‘유족 할인’ 정책을 문의했습니다. 챗봇은 “항공권 구매 후 90일 내에 신청하면 할인을 소급 적용받을 수 있다"고 자신 있게 답했습니다. 모팻은 이 말을 믿고 일반 요금으로 표를 구매했죠.
하지만 실제 정책은 달랐고, 에어캐나다는 환불을 거절했습니다. 사건이 법정으로 가자 에어캐나다는 “챗봇은 별개의 법적 주체이므로 우리는 책임이 없다"는 놀라운 주장을 펼쳤습니다. 재판부는 이 주장을 일축하며 “챗봇은 웹사이트의 일부이며, 에어캐나다는 웹사이트의 모든 정보에 책임이 있다"고 판결했습니다.
이 판결은 AI 시대의 기업 책임에 대한 중요한 선례를 남겼습니다. 기업은 AI가 저지른 실수를 “AI가 한 일"이라며 회피할 수 없다는 점을 명확히 한 것입니다. 이 사건은 AI 환각이 실제 금전적, 법적 책임을 초래하는 현실의 위험임을 보여주었습니다.
환각의 위험 스펙트럼
AI 환각의 위험성은 사소한 실수부터 치명적인 위협까지 다양합니다.
| 범주 | 사례 | 잠재적 결과 |
|---|---|---|
| 황당하고 재미있는 실수 | 스타벅스 라떼 한 잔에 50만원 | 잘못된 정보 전달, 사용자 혼란, 브랜드 이미지 손상 |
| 위험한 ‘조언’ | “피자에 접착제를 추가하세요” | 신체적 상해, 중독, 잠재적 사망 위험 |
| 금전적 및 법적 위험 | 챗봇이 잘못된 환불 정책 안내 | 소비자 금전적 손실, 기업의 법적 책임 발생 |
| 고도의 전문적 오류 | 존재하지 않는 법원 판례 인용 | 변호사 징계, 소송 패소, 사법 시스템 신뢰도 저하 |
| 치명적인 의료 위험 | “신장 결석 배출을 위해 소변을 마셔라” | 심각한 건강 악화, 적절한 치료 지연, 사망 |
전문가의 딜레마: 변호사마저 속이는 AI
환각의 위험은 전문가 영역까지 확장됩니다. 스탠퍼드 인간 중심 AI 연구소(Stanford HAI)에 따르면, 법률 관련 질문에 대한 범용 AI 모델의 환각 비율은 69%~88%에 달했습니다. 법률 연구용으로 개발된 고가의 전문 AI 도구조차 17%~33%의 환각을 일으켰습니다.
이는 변호사가 AI가 제시한 가짜 판례를 법원에 제출했다가 징계를 받는 실제 사건으로 이어지며, 전문 분야에서 AI를 활용할 때 극도의 주의가 필요함을 경고하고 있습니다.
AI 환각을 길들이는 최신 기술 3가지
다행히 전 세계 연구자들은 이 ‘똑똑한 거짓말쟁이’를 길들이기 위해 노력하고 있습니다. AI의 신뢰도를 높이는 세 가지 핵심 전략을 소개합니다.
전략 1: RAG - AI에게 똑똑한 참고서 쥐여주기
**검색 증강 생성(Retrieval-Augmented Generation, RAG)**은 AI에게 ‘오픈북 시험’을 보게 하는 기술입니다. AI가 자신의 기억에만 의존하는 대신, 답변 생성 전 최신 정보가 담긴 신뢰할 수 있는 데이터베이스(참고서)를 먼저 검색하도록 강제하는 방식입니다.
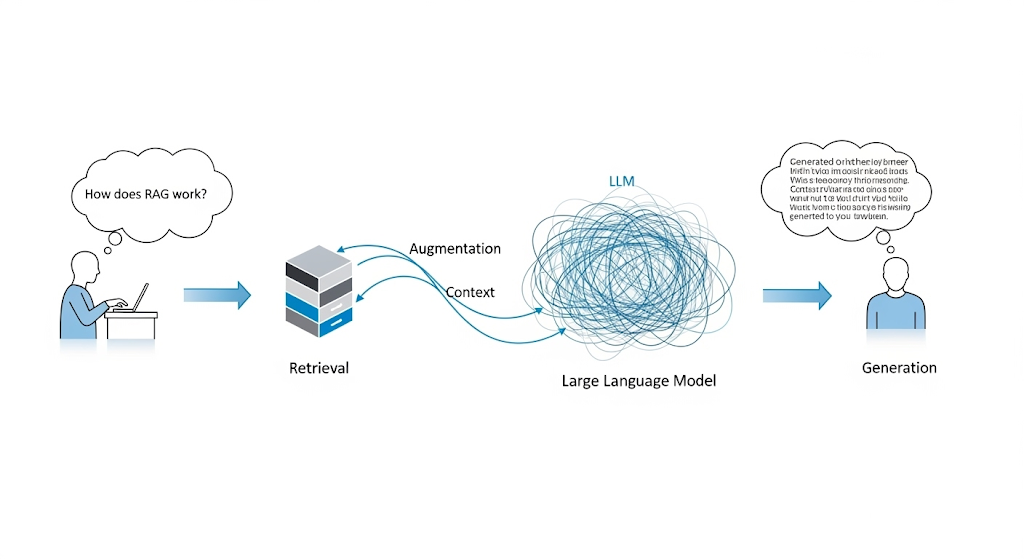
이 기술은 특히 의료 분야에서 큰 성공을 거두며 진단 정확도를 크게 높였습니다. 하지만 RAG가 만병통치약은 아닙니다. 앞서 언급한 스탠퍼드 법률 AI 연구에서 RAG 기반 도구들도 여전히 17%의 환각을 보인 것은 RAG의 한계를 보여줍니다. RAG는 외부 정보를 활용하는 강력한 보조 도구이지만, AI 내부의 추론 능력을 근본적으로 바꾸지는 못합니다.
Advertisement
전략 2: STaR & SoS - AI 스스로 생각하는 법 가르치기
두 번째 전략은 AI의 ‘생각하는 방식’ 자체를 개선하는 것입니다. 외부 참고서(RAG)를 넘어, 문제 해결 과정을 스스로 고민하고 배우게 하는 훈련법입니다.
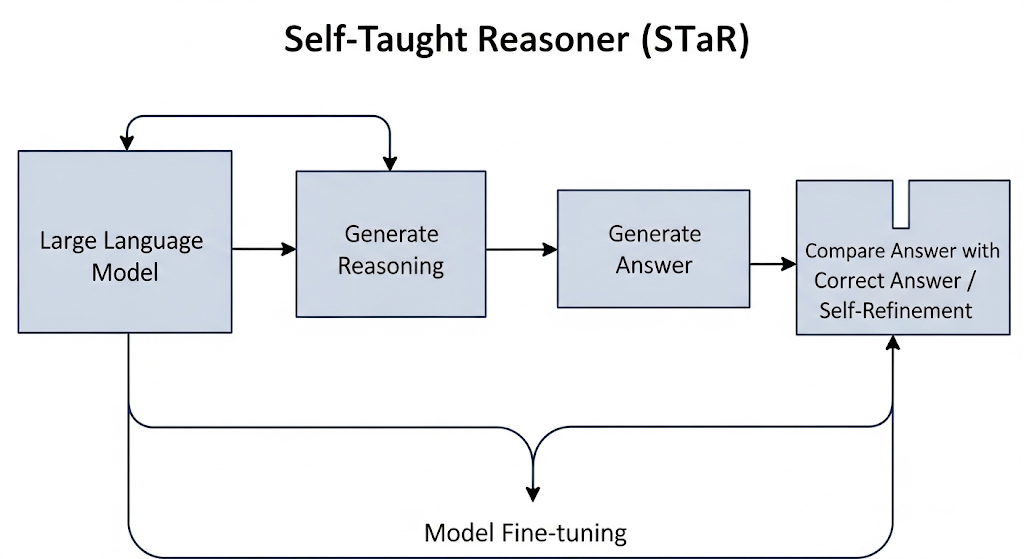
- STaR (Self-Taught Reasoner): “틀려도 괜찮아, 다시 풀어보자” **자율 학습 추론(STaR)**은 AI가 자신의 실수를 통해 배우게 합니다. AI가 틀린 답을 내면, 정답을 알려주고 “이 정답에 도달하려면 어떤 추론 과정을 거쳐야 했을까?“라고 되물어 올바른 과정을 역으로 학습시킵니다. 실패로부터 배우는 과정을 통해 AI는 스스로 추론 능력을 정교하게 다듬습니다.
- SoS (Stream-of-Search): “정답으로 가는 길은 여러 가지야” **탐색의 흐름(SoS)**은 한 단계 더 나아가, 정답뿐만 아니라 정답을 찾아가는 과정에서 겪는 수많은 시행착오와 실패 경로까지 통째로 학습시킵니다. 이를 통해 AI는 단순히 정답을 외우는 게 아니라, 현실적인 문제 해결을 위한 ‘탐색 전략’ 자체를 배우게 됩니다.
STaR와 SoS는 AI의 내적인 문제 해결 프로세스를 근본적으로 개선하려는 시도로, 모델의 본질적인 추론 능력을 향상시키는 중요한 패러다임 전환을 의미합니다.
전략 3: 도메인 특화 - 만물박사를 전문가로 키우기
세 번째 전략은 범용 AI를 특정 분야의 전문가로 만드는 **도메인 특화 미세조정(Fine-tuning)**입니다. 한국 기업들도 이 분야에서 두각을 나타내고 있습니다.
- 사례 1: SK텔레콤 & AWS SKT는 AWS와 협력하여 AI 모델 ‘클로드(Claude)‘를 통신 분야에 맞게 미세조정했습니다. 통신 관련 전문 데이터로 재훈련시킨 결과, 답변 품질은 58%, 출처 인용 정확도는 71% 향상되었습니다.
- 사례 2: BHSN & ‘앨리비 아스트로’ 국내 스타트업 BHSN이 개발한 법률 특화 LLM ‘앨리비 아스트로’는 방대한 법률 데이터와 변호사 피드백으로 개발되었습니다. 그 결과, 100페이지 분량의 영문 계약서를 1분 안에 검토하고 수정안까지 제시하는 전문가 수준의 역량을 갖추게 되었습니다.

이러한 사례들은 환각을 줄이고 현장에서 유용한 가치를 창출하는 가장 현실적인 길이 ‘전문화’에 있음을 보여줍니다.
결론: AI 시대, 비판적 사고는 필수
AI 환각은 50만원짜리 커피 농담에서 시작해 실제 법적 책임을 묻는 현실의 문제로 다가왔습니다. 이 문제를 해결하기 위한 기술 혁신은 놀라운 속도로 진행되고 있지만, 현재 우리가 가져야 할 가장 중요한 자세는 **‘건강한 회의주의’와 ‘비판적 사고’**입니다.
핵심 요점 3가지
- AI 환각은 단순 버그가 아닌 기술의 본질적 한계입니다. AI는 의미를 이해하는 것이 아니라 확률적으로 가장 그럴듯한 답변을 생성합니다.
- AI의 답변은 항상 검증이 필요합니다. 특히 의료, 금융, 법률 등 중요한 정보는 반드시 신뢰할 수 있는 출처를 통해 교차 확인해야 합니다.
- 기술은 빠르게 발전하고 있습니다. RAG, STaR, 도메인 특화 같은 기술들이 AI의 신뢰도를 높이고 있지만, 완벽한 해결책은 아직 없습니다.
AI를 모든 것을 아는 현자로 착각해서는 안 됩니다. 똑똑하지만 가끔은 터무니없는 실수를 하는 인턴사원처럼 대하는 지혜가 필요합니다. AI를 맹신하기보다, 우리의 판단력을 보조하는 강력한 도구로 활용할 때 그 진정한 가치를 발견할 수 있을 것입니다.
참고자료
- Lifehacker, What People Are Getting Wrong This Week: Google AI Hallucinations
- CanLII, Moffatt v. Air Canada, 2024 BCCRT 149
- JAMIA, Retrieval-augmented generation for large language models in biomedicine: a systematic review
- AI타임스, BHSN, 법률 특화 LLM ‘앨리비 아스트로’ 출시
- Stanford HAI, Hallucinating the Law: Legal Mistakes in Large Language Models Are Pervasive
- arXiv, STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
- OpenReview, Stream of Search (SoS): Learning to Search in Language
- AWS Machine Learning Blog, SK Telecom improves telco-specific Q&A by fine-tuning Anthropic’s Claude models in Amazon Bedrock