AI 제국을 건설한 보이지 않는 해자(Moat), CUDA의 모든 것
섹션 1: 제국의 초석: CUDA 해자(Moat) 해부
엔비디아의 막강한 지배력, 그 비밀은 단순히 뛰어난 반도체 칩에만 있는 게 아니에요. 사실은 10년 넘게 공들여 쌓아 올린, 누구도 넘보기 힘든 ‘소프트웨어 해자(Moat)’ 덕분이랍니다. 이번 섹션에서는 바로 그 핵심, CUDA가 어떻게 AI 혁명의 기반이 되었는지 기술적, 전략적 관점에서 샅샅이 파헤쳐 보겠습니다. 저도 개발자로서 처음 CUDA를 접했을 때 그 성능과 생태계의 편리함에 놀랐던 기억이 있습니다.
1.1. 그래픽을 넘어 범용 컴퓨팅으로: CUDA의 탄생
GPU 컴퓨팅의 초창기, 개발자들은 그래픽 처리를 위해 만들어진 OpenGL이나 Direct3D 같은 API를 범용 컴퓨팅 작업에 억지로 활용해야 하는 어려움을 겪었어요. 이는 높은 수준의 전문 지식이 필요했을 뿐만 아니라, GPU의 진정한 잠재력인 병렬 컴퓨팅 능력을 100% 끌어내기엔 역부족이었죠.
2006년, 엔비디아는 이 판도를 완전히 뒤집을 **CUDA(Compute Unified Device Architecture)**를 세상에 내놓았습니다. CUDA 덕분에 개발자들은 자신들에게 익숙한 C언어와 비슷한 방식으로 GPU의 수많은 병렬 처리 장치에 직접 접근할 수 있게 되었어요. 이는 **GPGPU(General-Purpose computing on Graphics Processing Units)**의 진입 장벽을 획기적으로 낮춘 사건이었고, 엔비디아가 개발자 중심의 거대한 생태계를 만드는 첫걸음이었습니다.
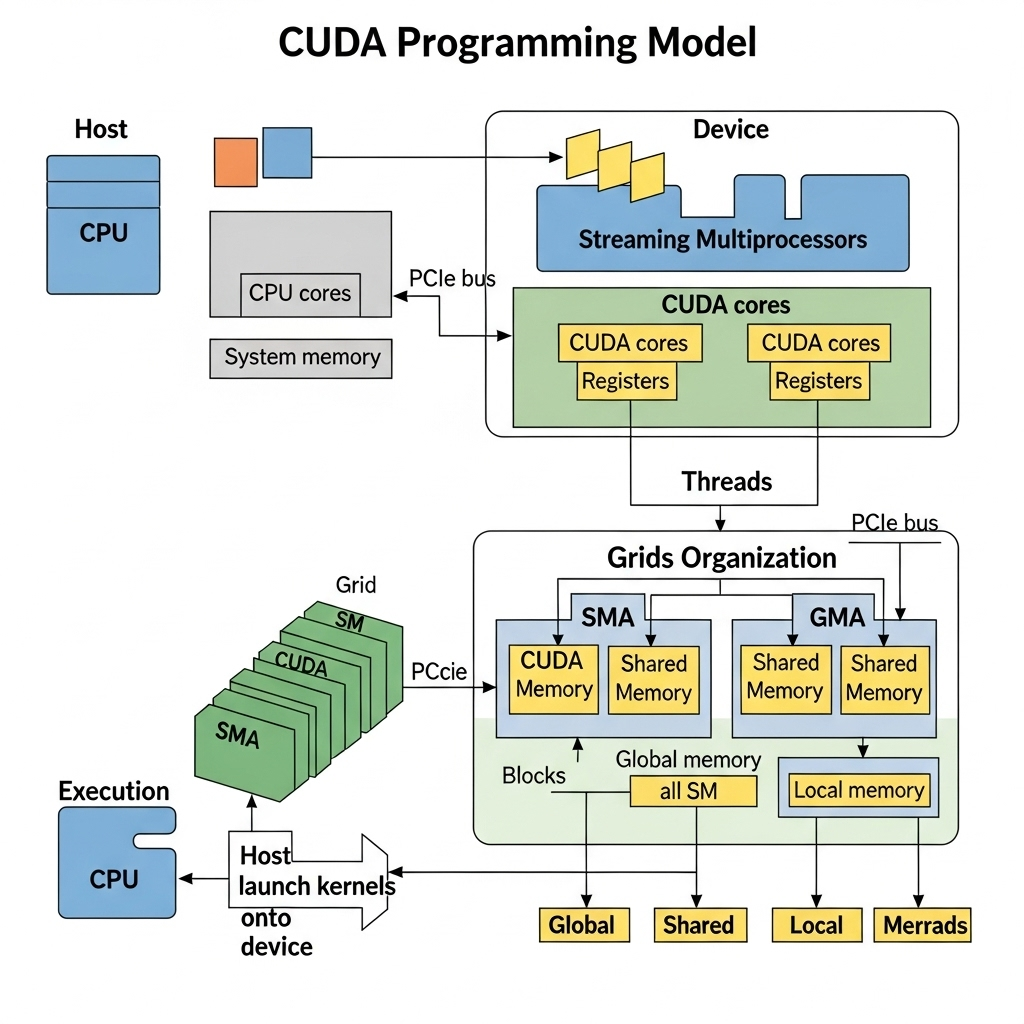
CUDA의 프로그래밍 모델은 역할 분담이 아주 명확해요. 시스템의 주 프로세서인 CPU는 ‘호스트(Host)’, 병렬 연산을 도맡는 GPU는 ‘디바이스(Device)’ 역할을 하죠. 개발자는 GPU에서 병렬로 돌릴 함수, 즉 **‘커널(Kernel)’**을 __global__이라는 키워드로 정의하기만 하면 됩니다. 데이터 처리 과정은 보통 이렇습니다:
- 호스트 메모리(RAM)에서 디바이스 메모리(VRAM)로 데이터를 복사하고,
- 호스트(CPU)가 디바이스(GPU)에 커널 실행을 명령하면,
- GPU의 수많은 코어가 커널 코드를 동시에 실행해 데이터를 처리한 뒤,
- 처리된 결과를 다시 호스트 메모리로 가져옵니다.
이처럼 간단하고 명료한 구조 덕분에 개발자들은 더 이상 복잡한 그래픽 API의 속사정을 몰라도 GPU의 강력한 연산 능력을 마음껏 활용할 수 있게 되었습니다. 이는 단순히 기술적 편의를 넘어, 수많은 연구자와 개발자들이 AI와 고성능 컴퓨팅(HPC) 분야로 뛰어드는 계기가 되었죠.
1.2. 락인(Lock-in)의 기술적 아키텍처: 커널, 스레드, 그리고 메모리 계층
CUDA가 강력하면서도 한번 발을 들이면 빠져나오기 힘든 이유는 그 기술적 구조 자체에 숨어있습니다. 엔비디아는 개발자들이 최고의 성능을 뽑아낼 수 있는 정교한 도구를 주면서, 동시에 이 도구들이 자사 하드웨어에 완벽하게 최적화되도록 설계해 자연스럽게 **‘락인 효과’**를 만들어냈습니다.
- 병렬 처리 모델: CUDA는 **‘스레드(Thread)’, ‘블록(Block)’, ‘그리드(Grid)’**라는 계층 구조로 병렬 처리를 관리해요. 스레드가 가장 작은 연산 단위고, 여러 스레드가 모여 블록을, 여러 블록이 모여 그리드를 이루죠. 이 모델을 통해 개발자들은 작업을 수만 개로 쪼개 GPU의 수천 개 코어에 효율적으로 나눠줄 수 있습니다. 이 강력한 모델은 개발자에게 ‘엔비디아 방식’의 병렬 프로그래밍 사고를 요구하고, 여기에 익숙해진 개발자는 다른 아키텍처로 넘어가기 어려워집니다.
- 메모리 계층의 우위: CUDA의 또 다른 핵심 경쟁력은 정교한 메모리 모델에 있어요. 특히, 각 스레드 블록 안에서 아주 빠른 속도로 데이터를 공유할 수 있는 **‘공유 메모리(Shared Memory)’**는 개발자가 직접 관리하는 캐시처럼 작동합니다. 이는 알고리즘 최적화의 핵심 요소죠. 또한, 통합 가상 메모리나 통합 메모리 같은 기능들은 CPU와 GPU 메모리 공간을 하나로 합쳐 프로그래밍을 더 쉽게 만들어 주었습니다. 이런 기능들은 경쟁 플랫폼이 쉽게 따라 할 수 없는 CUDA만의 강력한 무기입니다.
- 컴파일러와 개발 도구: 엔비디아의 컴파일러(NVCC)는 CUDA 코드에서 CPU용 코드와 GPU용 코드를 알아서 분리하고 최적화하는 핵심 역할을 합니다. 여기에 디버거, 프로파일러 등 수년간 다듬어진 성숙한 개발 도구 생태계는 경쟁사들이 따라오기 힘든 격차를 만들었고, 개발자들이 CUDA를 선택하는 중요한 이유가 되었습니다.
1.3. 개발자들이 CUDA를 선택한 이유: 성능, 안정성, 그리고 생태계
CUDA의 성공은 단순히 기술 하나가 좋아서가 아니에요. 뛰어난 성능, 안정적인 API, 방대한 라이브러리, 그리고 풍부한 문서와 커뮤니티 지원이 모두 합쳐진 결과물이죠. 특히 개방형 표준이었던 OpenCL과의 경쟁에서 그 차이가 명확히 드러났습니다.
OpenCL은 여러 제조사의 하드웨어에서 돌아간다는 이식성을 장점으로 내세웠지만, 오히려 이게 발목을 잡았어요. 새로운 하드웨어 기능이 나와도 표준에 반영되기까지 오래 걸렸고, 제조사마다 지원 수준과 성능이 제각각이라 파편화가 심각했죠. 개발자들 사이에서는 OpenCL 사용 경험을 “선인장을 껴안는 것 같다"고 표현할 정도였습니다.
반면, 엔비디아는 CUDA를 자사 하드웨어와 긴밀하게 통합해 개발했습니다. 특정 하드웨어에 종속된다는 단점은 있었지만, 새로운 GPU가 나올 때마다 그 성능을 100% 활용하는 기능을 빠르게 추가할 수 있는 강력한 무기가 되었죠. 심지어 엔비디아는 자사의 OpenCL 구현을 일부러 미흡하게 만들어 개발자들이 자연스레 성능이 더 좋은 CUDA로 넘어가도록 유도하는 전략을 쓰기도 했습니다.
Advertisement
이러한 전략은 엄청난 네트워크 효과를 낳았습니다. 더 많은 개발자가 CUDA를 쓰니 더 많은 라이브러리와 도구가 생겨났고, 이는 다시 더 많은 개발자를 끌어들이는 선순환 구조를 만들었죠. AI 연구자들이 CUDA 기반의 코드와 논문을 발표하면서 CUDA는 이 분야의 **‘공용어(lingua franca)’**가 되었습니다. 후발 연구자들은 기존 연구를 이어가기 위해 CUDA를 배워야만 했고, 이는 생태계의 락인 효과를 더욱 단단하게 만들었습니다. 결국 엔비디아의 성공은 개발자 경험에 대한 길고 집요한 투자가 어떻게 압도적인 시장 지배력으로 이어지는지를 보여주는 플랫폼 경제학의 교과서적인 사례입니다.
섹션 2: 풀스택(Full Stack) 구축: 엔비디아의 통합 생태계 전략
엔비디아의 야망은 CUDA라는 소프트웨어 해자에만 머무르지 않습니다. 이들은 단순한 부품 공급업체를 넘어, 하드웨어부터 소프트웨어, 서비스까지 모든 것을 아우르는 ‘엔드투엔드(end-to-end) 솔루션’ 제공업체로 변신하고 있습니다. 더 높은 마진을 확보하고 생태계를 더욱 끈끈하게 만드는 ‘풀스택’ 전략, 그 거대한 그림을 자세히 들여다보겠습니다.
2.1. 코어를 넘어서: 최적화 라이브러리의 역할 (cuDNN, TensorRT)
엔비디아는 CUDA 위에 특정 분야, 특히 AI를 위한 고도로 최적화된 라이브러리들을 겹겹이 쌓아 올렸습니다. 덕분에 개발자들은 복잡한 저수준 코딩 없이도 최고의 성능을 손쉽게 얻을 수 있게 되었고, CUDA의 지배력은 한층 더 강화되었죠.
- cuDNN (CUDA Deep Neural Network library): 이 라이브러리는 컨볼루션, 풀링 등 딥러닝의 핵심 연산을 최고 수준으로 최적화한 부품(primitive) 형태로 제공합니다. PyTorch나 TensorFlow 같은 유명 딥러닝 프레임워크들은 모두 내부적으로 cuDNN을 사용해 엔비디아 GPU에서 연산을 가속합니다. 사실상 전 세계 AI 개발자들은 자신도 모르는 사이에 CUDA 생태계의 강력한 성능에 의존하고 있는 셈이죠.
- TensorRT: TensorRT는 딥러닝 추론(inference) 단계에 특화된 최적화 도구입니다. 학습이 끝난 AI 모델을 받아 실제 서비스 환경에 맞게 압축하고 다듬어, 가장 빠른 속도와 최대 처리량을 내도록 도와주죠. TensorRT는 AI 모델의 학습부터 배포, 추론에 이르는 전 과정에서 기업들이 엔비디아 생태계를 벗어날 수 없게 만드는 결정적인 역할을 합니다.
2.2. 턴키 솔루션: DGX 시스템과 “상자 안의 AI 슈퍼컴퓨터”
엔비디아는 개별 GPU 칩을 파는 데 그치지 않고, 완벽하게 통합된 솔루션을 판매하는 데 집중하고 있습니다. 기업 고객들이 겪는 복잡한 인프라 구축 문제를 한 번에 해결해주고, 그 대가로 높은 프리미엄을 받는 전략이죠.

- 역사와 진화: 2016년 DGX-1을 시작으로 DGX H100, 그리고 최신 DGX GB200에 이르기까지, 엔비디아는 AI 연산 요구량이 폭발적으로 증가함에 따라 끊임없이 성능과 통합 수준을 높여왔습니다.
- 전략적 합리성: DGX 시스템은 단순한 서버가 아닙니다. “엔터프라이즈 AI를 위한 업계 표준 솔루션"으로 자리매김했죠. 각 시스템에는 최신 GPU는 물론, GPU 간 초고속 통신을 위한 NVLink, 고성능 스토리지, 그리고 최적화된 소프트웨어 스택까지 모두 포함되어 있습니다. 이렇게 미리 구성된 ‘턴키(turn-key)’ 방식 덕분에 기업들은 AI 인프라를 구축하고 안정화하는 데 걸리는 시간을 수개월에서 단 몇 시간으로 줄일 수 있습니다. 이 압도적인 편의성이 바로 높은 가격을 정당화하고, 인프라 수준에서 강력한 락인 효과를 만들어내는 비결입니다.
2.3. 수직 통합: 멜라녹스(Mellanox) 인수와 네트워킹의 전략적 중요성
2019년, 엔비디아가 네트워킹 기술 기업 멜라녹스를 69억 달러에 인수한 것은 플랫폼 전략의 화룡점정이었습니다. 현대의 대규모 AI 데이터센터에서는 GPU 성능만큼이나 네트워킹이 중요하기 때문이죠. 멜라녹스는 고성능 컴퓨팅 분야의 표준 기술인 **인피니밴드(InfiniBand)**의 선두주자였습니다. 이 인수로 엔비디아는 서버 안의 GPU 간 통신은 물론, 수많은 서버를 연결하는 클러스터 전체의 데이터 경로까지 완벽하게 통제할 수 있게 되었습니다.
이러한 수직 통합은 여러 서버에 흩어져 있는 GPU들이 CPU를 거치지 않고 네트워크를 통해 직접 데이터를 교환하게 하는 GPUDirect RDMA 같은 독점 기술을 가능하게 했습니다. 이는 대규모 분산 학습의 성능을 극적으로 향상시키며, 단순히 GPU 칩만 파는 경쟁사들은 결코 따라올 수 없는 강력한 시스템 수준의 경쟁 우위를 만들어주었습니다.
2.4. 서비스형 플랫폼: AI Enterprise와 DGX Cloud
엔비디아는 이제 하드웨어와 저수준 소프트웨어를 넘어, 아마존웹서비스(AWS)를 떠올리게 하는 서비스형 소프트웨어(SaaS) 및 클라우드 서비스로 사업을 확장하며 풀스택 비전을 완성하고 있습니다.
- NVIDIA AI Enterprise: 기업 환경에서 AI 모델을 개발, 배포, 관리하기 위한 포괄적인 소프트웨어 묶음입니다. 구독 기반으로 판매되어 엔비디아에게 안정적인 수익을 가져다주는 동시에, 기업 고객들의 생태계 의존도를 더욱 깊게 만듭니다.
- DGX Cloud: 주요 클라우드 서비스 제공업체(CSP)의 데이터센터에 엔비디아의 DGX 인프라를 그대로 옮겨와 클라우드 서비스 형태로 제공하는 것입니다. 이를 통해 엔비디아는 퍼블릭 클라우드 환경에서조차 최고의 AI 플랫폼은 엔비디아의 것임을 확실히 각인시키고 있습니다.
나아가 엔비디아는 디지털 트윈을 위한 옴니버스(Omniverse), 로보틱스 개발을 위한 Isaac 플랫폼 등을 통해 산업 자동화, 자율주행차 같은 거대 신규 시장까지 공략하고 있습니다. 이는 엔비디아의 생태계가 AI를 넘어 물리 세계의 시뮬레이션과 자동화까지 확장되고 있음을 보여줍니다.
이러한 풀스택 전략의 정점에는 최근 주목받은 Run:ai 인수가 있습니다. Run:ai는 GPU 자원을 가상화하고 효율적으로 관리하는 소프트웨어를 만드는 기업이죠. 겉보기엔 GPU 활용도를 높이는 기술이 GPU 판매량을 줄일 위협처럼 보일 수 있습니다. 하지만 더 깊이 들여다보면, GPU 자원의 할당과 관리를 통제하는 **‘오케스트레이션 레이어’**를 장악하는 기업이 새로운 문지기가 된다는 전략적 계산이 깔려 있습니다. 엔비디아는 이 계층을 직접 통제함으로써, 고객들이 GPU 사용을 최적화하려 할 때조차도 엔비디아의 생태계 안에서 하도록 만듭니다. 이는 제3의 플랫폼이 등장해 GPU를 단순 부품(commodity)으로 만들어버리는 상황을 미리 차단하는, 아주 영리한 방어 전략이라 할 수 있습니다.
Advertisement
섹션 3: 요새를 향한 공격: 도전자들의 유형 분석
엔비디아의 독점에 맞서는 경쟁 환경은 어떨까요? 이번 섹션에서는 도전자들을 전략적 접근 방식에 따라 분류하고, 각자의 강점과 약점, 그리고 성공 가능성을 냉정하게 평가해 보겠습니다.
3.1. 미러(Mirror) 전략: AMD의 ROCm과 CUDA 호환성을 향한 여정
AMD의 핵심 전략은 **ROCm(Radeon Open Compute Platform)**을 통해 CUDA와 비슷하면서도 오픈 소스인 대안을 제공하는 것입니다. 특히 HIP(Heterogeneous-compute Interface for Portability) API는 기존 CUDA 코드를 약간만 수정하면 ROCm에서 실행할 수 있도록 설계되어, 개발자들의 전환 장벽을 낮추는 것을 목표로 하죠.
하드웨어만 보면 AMD의 Instinct 가속기, 특히 MI300X는 상당한 경쟁력을 갖췄습니다. 192GB에 달하는 방대한 메모리는 엔비디아 H100/H200을 능가하는 사양으로, 거대 언어 모델(LLM)처럼 메모리가 많이 필요한 작업에서 이론적으로는 더 유리합니다.
하지만 결정적인 문제는 소프트웨어에 있습니다. 하드웨어 스펙이 아무리 좋아도, ROCm 생태계는 아직 미성숙하고, 설치가 복잡하며, 버그가 많다는 평가를 받습니다. 여러 벤치마크 결과를 보면, 일반 사용자가 접하는 순정 상태의 ROCm 성능은 기대에 못 미치고, 최고 성능을 내려면 AMD 엔지니어의 특별 지원을 받은 전용 소프트웨어가 필요한 경우가 많습니다. 이 **‘소프트웨어 갭’**이야말로 AMD가 뛰어난 하드웨어를 실제 시장 점유율로 바꾸지 못하는 근본적인 원인입니다.
표 1: LLM 워크로드 성능 벤치마크 요약: NVIDIA H200 vs AMD MI300X
| 구분 | NVIDIA H200 (CUDA) | AMD MI300X (ROCm) |
|---|---|---|
| 메모리 용량 | 141GB HBM3e | 192GB HBM3 (우위) |
| LLM 추론 처리량 | 우위 (TensorRT-LLM) | 열위 (vLLM) |
| LLM 학습 처리량 | 우위 | 열위 |
| 대규모 확장성 | 압도적 우위 (NCCL) | 심각한 열위 (RCCL) |
| 소프트웨어 성숙도 | 매우 높음 | 낮음 (불안정, 버그) |
결론적으로, MI300X는 넉넉한 메모리 덕분에 특정 추론 작업에서는 경쟁력이 있지만, 학습 성능과 특히 여러 GPU를 묶어 쓰는 대규모 확장성 면에서는 소프트웨어와 네트워킹 생태계의 미성숙함 때문에 엔비디아에 크게 뒤처집니다. 엔비디아의 차세대 칩인 Blackwell(B200)은 이 격차를 더욱 벌릴 것으로 예상됩니다.
3.2. 개방형 표준의 승부수: 인텔의 oneAPI와 벤더 중립성에 대한 베팅
인텔의 oneAPI는 AMD와는 다른 길을 갑니다. SYCL 같은 개방형 표준에 기반한 통합 프로그래밍 모델로, CPU, GPU, FPGA 등 다양한 제조사의 여러 가속기에서 모두 작동하도록 설계되었죠. oneAPI의 핵심 가치는 특정 회사에 종속되는 ‘벤더 락인’으로부터의 해방입니다.
하지만 oneAPI 역시 ROCm처럼 CUDA에 비해 생태계가 아직 초기 단계라는 과제를 안고 있습니다. 라이브러리 지원, 문서, 하드웨어별 성능 최적화 등에서 갈 길이 멀죠. 이론적으로는 이식성이 높지만, 실제 최고의 성능을 내려면 여전히 하드웨어별 튜닝이 필요합니다. 현재 인텔은 AI 가속기 시장에서 3위 사업자이며, oneAPI는 독점 솔루션보다 개방형 표준이 더 높은 가치를 인정받는 미래에 대한 장기적인 베팅이라고 할 수 있습니다. 그 성공은 인텔 자체 가속기(예: Gaudi)의 성능과 oneAPI 표준이 업계에서 얼마나 폭넓게 채택되는지에 달려 있습니다.
3.3. 추상화의 위협: Triton과 Mojo는 하드웨어를 무의미하게 만들 수 있는가?
엔비디아에 대한 가장 강력하고 장기적인 위협은 어쩌면 하드웨어를 단순 부품으로 만들어버릴 수 있는 **‘추상화 계층(abstraction layer)’**에서 나올지도 모릅니다. 이들은 CUDA 해자의 근간을 뒤흔들 잠재력을 가지고 있습니다.
Advertisement
- OpenAI의 Triton: Triton은 고성능 GPU 커널을 작성하기 위한 Python 기반 언어입니다. 개발자가 NumPy처럼 쉬운 구문으로 코드를 짜면, Triton 컴파일러가 메모리 관리 등 전문가 수준의 복잡한 저수준 최적화를 자동으로 처리해주는 것이 핵심이죠. Triton의 목표는 Python 수준의 생산성으로 CUDA 수준의 성능을 내는 것입니다. 결정적으로 Triton은 오픈 소스이며 엔비디아와 AMD 백엔드를 모두 지원합니다.
- Modular의 Mojo: Mojo는 Python의 편리함과 C++/Rust의 성능을 결합한 새로운 프로그래밍 언어입니다. MLIR이라는 기술을 기반으로, CUDA에 의존하지 않고 CPU, GPU 등 다양한 하드웨어를 지원하도록 처음부터 설계되었죠. Mojo의 궁극적인 목표는 AI 개발 전체를 위한 단일 언어를 제공하여, 현재처럼 고수준 로직은 Python으로, 저수준 최적화는 C++/CUDA로 짜야 하는 ‘두 언어 문제’를 해결하는 것입니다.
- 실존적 위협: Triton과 Mojo는 모두 CUDA 해자의 기반을 직접 공격합니다. 만약 개발자들이 Python이나 Mojo로 짠 코드 하나로 모든 GPU(엔비디아, AMD, 인텔)에서 최고의 성능을 낼 수 있게 된다면, 하드웨어는 서로 교체 가능한 부품이 되어버립니다. 이는 CUDA 락인을 무너뜨리고, 엔비디아가 오직 하드웨어 성능만으로 경쟁하게 만들어 플랫폼 기반의 막강한 가격 결정력을 약화시킬 것입니다. 이는 기존 게임의 룰을 바꾸려는 시도이며, 때로는 게임을 더 잘하려는 경쟁자보다 게임의 룰을 바꾸는 경쟁자가 더 위험한 법입니다.
표 2: GPGPU 소프트웨어 플랫폼 비교 분석
| 속성 | CUDA | ROCm (HIP) | oneAPI (SYCL) | Triton | Mojo |
|---|---|---|---|---|---|
| 프로그래밍 모델 | C++ 확장, 독점 | C++ 기반, CUDA 유사 | C++ 기반, 개방형 | Python 기반 | Python 상위 집합 |
| 하드웨어 지원 | NVIDIA 전용 | AMD (주), NVIDIA | 벤더 중립 | NVIDIA, AMD | 벤더 중립 목표 |
| 생태계 성숙도 | 매우 높음 | 중간 | 낮음 | 중간 | 매우 낮음 |
| 핵심 강점 | 성능, 안정성 | 오픈 소스 | 벤더 중립성 | 높은 생산성 | Python 호환성 |
| 핵심 약점 | 벤더 락인 | 불안정성 | 생태계 부족 | 제한적 적용 | 초기 단계 |
섹션 4: 왕관의 무게: 전 세계적인 반독점 규제 압박
엔비디아의 압도적인 지배력은 필연적으로 전 세계 규제 당국의 감시를 불러왔습니다. 이번 섹션에서는 각국 규제 기관들이 엔비디아의 핵심 성공 전략인 CUDA 해자를 어떻게 법적 논리로 겨냥하고 있는지 심층적으로 분석해 보겠습니다.
4.1. 미국: 법무부(DOJ)의 끼워팔기, 번들링, 배타적 행위 조사
미국 법무부(DOJ)는 엔비디아의 플랫폼 전략 심장부를 정조준하고 있습니다. 조사의 핵심 혐의는 다음과 같습니다.
- 불법적 끼워팔기(Tying) 및 번들링(Bundling): 지배적 상품인 GPU를 팔면서 CUDA 같은 자사 소프트웨어 및 서비스를 불법적으로 연계해, 고객들을 생태계에 가두고 경쟁을 막았다는 혐의입니다.
- 배타적 거래(Exclusive Dealing): 엔비디아 제품만 독점적으로 쓰는 고객에게 가격, 물량, 기술 지원 등에서 혜택을 줌으로써 경쟁사 제품을 함께 쓰는 고객에게 불이익을 주었는지 여부입니다.
4.2. 유럽연합(EU) 및 프랑스: 시장 지배력 남용과 불공정 경쟁에 대한 초점
프랑스 경쟁 당국은 EU 차원의 감시 속에서 엔비디아 조사를 주도하고 있습니다. 이들은 “CUDA와 칩의 번들링이 잠재적으로 반경쟁적"이라고 명시적으로 지적하며 가격 담합, 공급 제한, 불공정 계약 조건 등을 문제 삼고 있습니다. 혐의가 인정되면 연간 매출의 최대 10%에 달하는 막대한 과징금이 부과될 수 있습니다.
4.3. 중국의 레버리지: 지정학적 도구로서의 반독점 규제
중국 역시 자체적인 반독점 조사를 시작했습니다. 이 조사는 엔비디아가 90%가 넘는 시장 점유율을 남용해 GPU와 멜라녹스 인수로 얻은 인피니밴드 네트워킹 기술을 묶어 팔고, 타사 네트워킹 솔루션의 성능을 제한하는지 여부에 초점을 맞추고 있습니다. 이는 미국의 첨단 칩 수출 통제에 맞서 중국이 협상력을 확보하려는 지정학적 카드로도 해석됩니다.

4.4. Run:ai 인수: 경쟁 억제를 위한 전략적 인수의 사례 연구
엔비디아의 Run:ai 인수는 규제 당국의 핵심 조사 대상입니다. 혐의의 논리는 매우 정교합니다. 즉, 엔비디아가 Run:ai의 기술을 통합하기 위해서가 아니라, GPU 사용을 더 효율적으로 만드는 기술을 ‘억제’하기 위해 인수했다는 것입니다. GPU 사용이 효율화되면 고객들은 더 적은 GPU를 사게 되어 엔비디아 매출에 타격을 주므로, 이런 위협을 미리 제거했다는 주장이죠. 이 혐의는 엔비디아를 단순히 비싼 독점 기업이 아니라, 기술 발전을 적극적으로 저해하는 기업으로 묘사하기 때문에 매우 파괴적인 파급력을 가질 수 있습니다.
표 3: 엔비디아에 대한 글로벌 반독점 조사 개요
| 관할권 | 주요 혐의 | 핵심 조사 대상 |
|---|---|---|
| 미국 (DOJ) | 끼워팔기, 배타적 거래, 반경쟁적 인수 | CUDA 번들, Run:ai 인수, 고객 차별 |
| EU / 프랑스 | 시장 지배력 남용, 가격 담합, 공급 제한 | CUDA와 하드웨어의 번들링 |
| 중국 (SAMR) | 시장 지배력 남용 (번들링), 공정 거래 위반 | GPU와 인피니밴드 기술 번들링 |
섹션 5: 엔비디아의 반격: 로드맵, 비전, 그리고 전략적 양보
물론 엔비디아도 가만히 앉아 당하고만 있지는 않습니다. 이들은 더 빠른 제품 출시 주기, 강력한 미래 비전 제시, 그리고 위협을 무력화하기 위한 정교한 ‘전략적 개방’ 카드를 통해 적극적으로 지배력을 방어하고 있습니다.
5.1. 1년 주기(Cadence)의 가속: Blackwell, Rubin, 그리고 그 너머
엔비디아는 최근 신제품 출시 주기를 2년에서 1년으로 단축하겠다고 발표했습니다. 이는 경쟁사들이 따라잡는 것을 불가능하게 만들려는 의도적인 전략이죠. 발표된 로드맵은 Hopper(2022), Blackwell(2024), Rubin(2026)으로 이어지며, GPU뿐만 아니라 CPU, 네트워킹까지 포함하는 완전한 플랫폼의 진화를 예고합니다. 이 공격적인 속도는 경쟁사와의 성능 격차를 계속 벌리는 동시에, 시장 전체가 엔비디아의 로드맵을 중심으로 움직이게 만들어 경쟁사들을 영원한 추격자로 고사시키려는 전략입니다.
Advertisement
5.2. “AI 팩토리”: 엔비디아의 엔터프라이즈 컴퓨팅 미래 비전
엔비디아는 단순히 하드웨어가 아닌, 하나의 ‘비전’을 판매합니다. 바로 **‘AI 팩토리’**라는 개념인데요, 기업들이 상품을 생산하기 위해 공장을 짓듯, 미래에는 지능을 생산하기 위해 AI 팩토리, 즉 데이터센터를 갖게 될 것이라는 비전입니다.
이 비전은 DGX, AI Enterprise 같은 엔비디아의 제품들을 새로운 산업 혁명을 위한 필수 설비로 자리매김시킵니다. 엔비디아를 기업 혁신의 근본적인 파트너로 포지셔닝하여 자사 플랫폼에 대한 막대한 투자를 정당화하는 강력한 마케팅 서사죠.
5.3. 오픈 소스 방어 전략: 선택적 개방성
반독점 압박과 오픈 소스 도전자들의 부상에 맞서, 엔비디아는 정교한 ‘전략적 개방’ 캠페인에 나섰습니다. 이는 독점 모델을 포기하는 것이 아니라, 비판을 무마하고 위협을 끌어안기 위한 계산된 움직임입니다.
엔비디아는 리눅스 드라이버의 커널 모듈이나, 최근 인수한 Run:ai 소프트웨어 같은 일부 구성 요소를 전략적으로 오픈 소스화했습니다. 이는 폐쇄적인 독점 기업이라는 비난을 피하는 동시에, “AMD 하드웨어에서 쓰고 싶으면 당신들이 직접 개발하라"는 식으로 경쟁사에게 책임을 떠넘기는 효과를 노립니다. 물론 가장 완벽하게 지원되는 버전은 엔비디아의 것이겠죠. 핵심인 CUDA 컴파일러와 GPU 하드웨어 설계는 여전히 굳건한 독점 자산으로 남겨둔 채, 덜 중요한 자산을 내어주고 핵심을 지키는 정교한 유도 전략입니다.
결론
지금까지 엔비디아의 CUDA 플랫폼이 어떻게 AI 시대의 절대 강자로 자리매김했는지, 그리고 어떤 도전에 직면했는지 살펴보았습니다. 엔비디아의 미래는 네 가지 힘의 상호작용에 의해 결정될 것입니다.
핵심 요약:
- 굳건한 해자: CUDA는 단순한 소프트웨어를 넘어, 10년 이상 축적된 라이브러리, 개발 도구, 커뮤니티를 포함하는 압도적인 생태계입니다.
- 도전의 유형: AMD와 인텔의 직접적인 경쟁 외에도, Triton/Mojo 같은 하드웨어 추상화 계층이 CUDA의 락인 효과를 무너뜨릴 수 있는 더 근본적인 위협입니다.
- 미래 시나리오: 엔비디아의 지배력은 계속될 수도 있지만(The Moat Holds), 추상화 계층으로 인해 약화되거나(The Moat Erodes), 강력한 반독점 규제로 인해 무너질(The Moat is Breached) 가능성도 존재합니다.
중기적으로는 엔비디아의 지배력이 상당 부분 유지되겠지만, 오픈 소스 기반의 ‘개방형 추상화’ 움직임은 장기적으로 가장 큰 변수가 될 것입니다. 여러분은 엔비디아의 독점이 앞으로 어떻게 변화할 것이라고 생각하시나요?
참고자료
- CUDA 개념 및 CUDA 초급 예제 (1/2) - MangKyu’s Diary 링크
- CUDA - 위키백과, 우리 모두의 백과사전 링크
- CUDA (쿠다) 란, 왜 사용하는 것인가. - 내꿈은자동화 링크
- The CUDA Empire - Medium 링크
- CUDA vs OpenCL - Andreas Klöckner’s Former Wiki 링크
- What about OpenCL and CUDA C++ alternatives? - Modular Blog 링크
- NVIDIA cuDNN 9로 트랜스포머 가속화 - NVIDIA Developer Blog 링크
- TensorRT란? - OPAC 링크
- NVIDIA DGX 시스템 - 비엔아이엔씨 링크
- 엔비디아(NVIDIA) 인수합병(M&A)과 비즈니스 성장 전략 - acqu1esce’s Blog 링크
- “더이상 칩 회사 아냐”…아마존 닮아가는 엔비디아, 플랫폼 전략은? - 이데일리 링크
- Department of Justice Begins Antitrust Probe into Nvidia - HPCwire 링크
- A Comprehensive Guide: Switching from CUDA to ROCm - TensorWave 링크
- MI300X vs H100 vs H200 Benchmark Part 1: Training – CUDA Moat Still Alive - SemiAnalysis 링크
- oneAPI: A Viable Alternative To CUDA* Lock-in - Intel 링크
- Introducing Triton: Open-source GPU programming for neural networks - OpenAI 링크
- Welcome to Triton’s documentation! 링크
- Mojo : Powerful CPU+GPU Programming - Modular 링크
- The DOJ and Nvidia: AI Market Dominance and Antitrust Concerns - AAF 링크
- 로이터 “프랑스, 엔비디아 반독점법 위반으로 제재 예정” - 한겨레 링크
- Key Analysis of China’s Antitrust Investigation into Nvidia - Ming-Chi Kuo 링크
- 새로운 소식이 넘치는 ‘GTC 2025’ 하이라이트 - NVIDIA Blog Korea 링크
- NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules - NVIDIA Developer Blog 링크